
簡単なFashionMNIST用モデルでPyTorchとPyTorch Lightningを比較してみた

こんちには。
データアナリティクス事業本部機械学習チームの中村です。
今回は、PyTorch Lightningについて簡単なお題を使って紹介していきます。
PyTorch Lightningの概要
PyTorch Lightningは、PyTorchの高水準インターフェースを提供するライブラリです。
機械学習のコア部分のロジックを、定型的な実装部分から切り離して定義できるようなインターフェースに工夫されています。 そのためユーザーは、機械学習のコア部分のロジックの検討に集中することができます。
PyTorch Lightningには、以下のような特徴があります。
- 統一的なコーディングが可能
- 定義済みのHooksに沿えばフォーマット化されるため属人性が低下
- 良く使用するEarlyStoppingなどは、コールバックとして定義済み
- 定型的な処理を隠蔽化
- 学習ループなどの記述が不要
- 勾配関連の処理が不要(
optimizer.zero_grad()やtorch.no_grad()) - 勾配関連の処理が原因となるようなメモリ枯渇もなくなる
- プログレスバーなどの表示が自動化
- デバイス依存関係の処理が不要もしくは切り替えが容易に
.to(device)などの記述が不要- GPU/TPU/IPUでの学習に対応、また複数GPUの並列計算にも対応
- 様々な実験管理ライブラリに対応
- TensorBoard、MLFlow、Comet、Neptune、wandbなどに対応
- 高速化の検討に必要なツールを準備
- プロファイリングが可能でモデルのボトルネックなどを調査できる
GitHubのスター数のトレンドとしても勢いがあります。
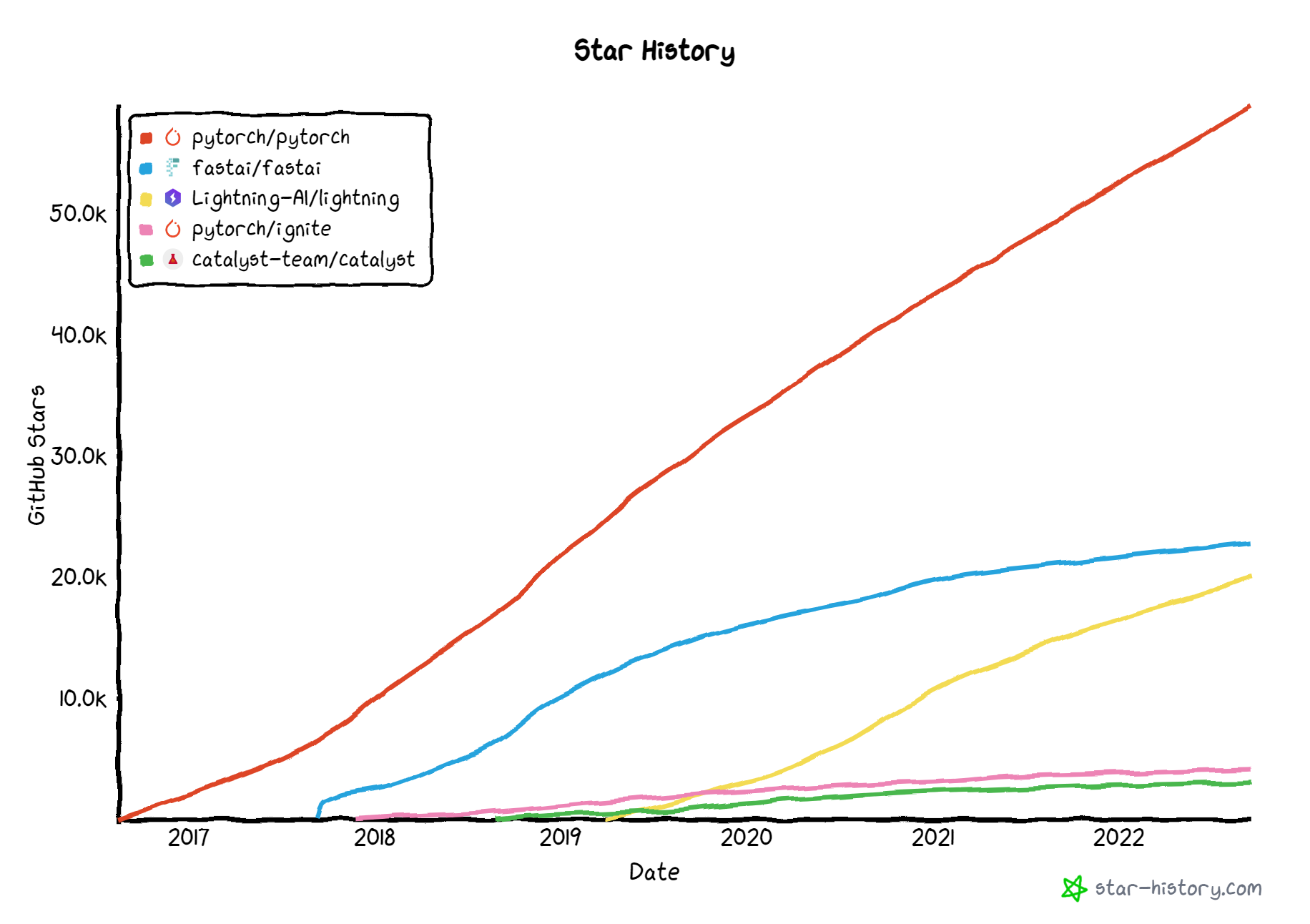
(PyTorchそのものや、より高水準なfastaiには及ばないものの、 同水準の他ライブラリ(Ignite、Catalyst)よりは勢いがある)
題材とするタスクとモデル、学習戦略について
タスクはFashion-MNISTを用います。
モデルは以下のような中間層1つのシンプルな全結合層からなるネットワークとします。
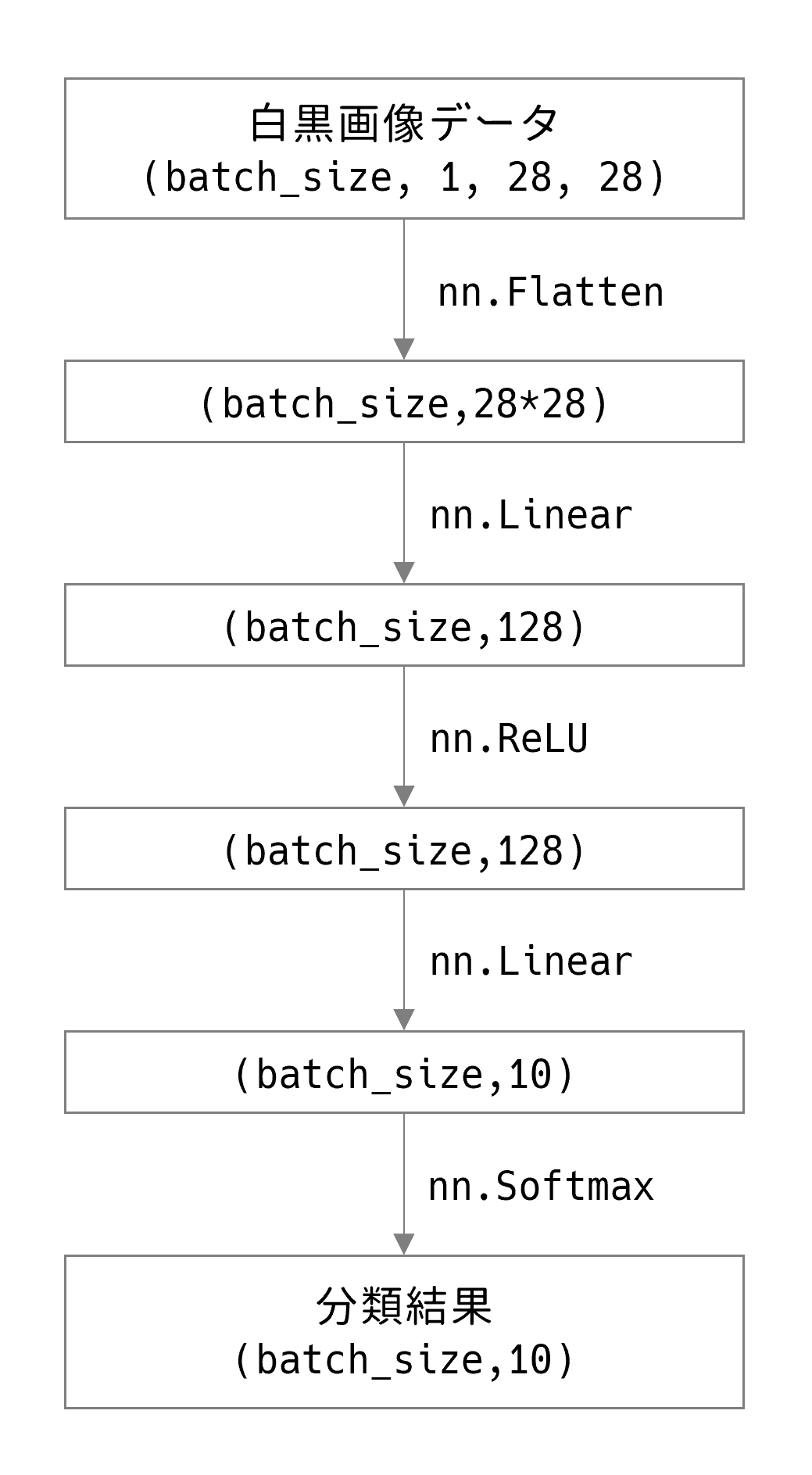
その他学習戦略としては最低限な以下を準備します。
- パラメータの最適化にはAdamを使用する
- Early Stoppingで学習を自動停止する
実行環境
今回はGoogle Colaboratory環境で実行しました。
ハードウェア情報は以下の通りです。
- GPU: Tesla P100 (GPUメモリ16GB搭載)
- メモリ: 26GB
主なソフトウェア・ライブラリのバージョンは以下となります。
- CUDA: 11.2
- PyTorch: 1.12.0+cu113
- PyTorch Lightning: 1.7.6
事前の定義
パラメータをクラスで定義しておきます。
class MyParameters():
max_epochs: int = 30
early_stopping: bool = True
early_stopping_patience: int = 3
batch_size: int = 32
learning_rate: float = 0.001
params = MyParameters()
まず基本のPyTorch
インポート
必要なライブラリをインポートします。
import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor from tqdm import tqdm import pathlib
データのロード
FashionMNISTをロードします。trainとtestがありますが、今回は簡易のためtestをvalidとして使用していきます。
train_data = datasets.FashionMNIST(root="data", train=True ,
download=True, transform=ToTensor())
valid_data = datasets.FashionMNIST(root="data", train=False,
download=True, transform=ToTensor())
モデル定義
nn.Moduleを継承して、__init__とforwardを実装する必要があります。
class SamplePyTorchModel(nn.Module):
def __init__(self):
super(SamplePyTorchModel, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
トレーニング
トレーニング部分を記述します。長くなるため、説明はコード上にコメントで記載します。
# CPU/GPU設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device")
# モデルをインスタンス化
model = SamplePyTorchModel().to(device)
# オプティマイザ定義
# モデルパラメータをオプティマイザに渡す必要がある
optimizer = torch.optim.Adam(model.parameters(), lr=params.learning_rate)
# 損失関数の定義
# NOTE: softmaxを含んでいるので要注意
loss_fn = nn.CrossEntropyLoss()
# DatasetはDataLoader経由でイテレーションする
train_dataloader = DataLoader(train_data, batch_size=params.batch_size)
valid_dataloader = DataLoader(valid_data, batch_size=params.batch_size)
# Early stopping用
valid_loss_min = None
patience_count = 0
# epochのループ
for epoch in range(params.max_epochs):
print(f"Epoch {epoch+1}/{params.max_epochs}")
# train結果集計用の変数
train_loss, train_correct = 0, 0
# train用ループ
for X, y in tqdm(train_dataloader,
total=len(train_dataloader), ascii=True, desc="train"):
X, y = X.to(device), y.to(device)
# 推論
pred = model(X)
# ロス計算
loss = loss_fn(pred, y)
# backward前に前回のbackward時の勾配情報をクリア
optimizer.zero_grad()
# 誤差逆伝搬
loss.backward()
# 各パラメータを更新
optimizer.step()
# ロスの値を加算
# NOTE: itemを記述しないと、train_loss変数にすべてのエポック情報が蓄積されるので注意
train_loss += loss.item()
# 正解数をカウント
train_correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# ロスの平均化
num_batches = len(train_dataloader)
train_loss = train_loss / num_batches
# 正解数を正解率に換算
size = len(train_dataloader.dataset)
train_accuracy = train_correct / size
# 勾配計算をしないようにするコンテキストマネージャ
with torch.no_grad():
# valid結果集計用の変数
valid_loss, valid_correct = 0, 0
# valid用のループ
for X, y in tqdm(valid_dataloader,
total=len(valid_dataloader), ascii=True, desc="valid"):
X, y = X.to(device), y.to(device)
# 推論
pred = model(X)
# ロス計算
loss = loss_fn(pred, y)
# ロスの値を加算
valid_loss += loss.item()
# 正解数をカウント
valid_correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# ロスの平均化
num_batches = len(valid_dataloader)
valid_loss = valid_loss / num_batches
# 正解数を正解率に換算
size = len(valid_dataloader.dataset)
valid_accuracy = valid_correct / size
print(f"loss: {train_loss:.3f} - accuracy: {train_accuracy:.3f} \
- val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
if params.early_stopping:
# valid_lossの最小値更新できた場合
if valid_loss_min is None or valid_loss < valid_loss_min:
# 最小値を更新
valid_loss_min = valid_loss
# カウンタをクリア
patience_count = 0
# ベストなパラメータを記憶
best_params = model.state_dict().copy()
# 保存
dirpath = pathlib.Path(f'./pytorch-checkpoints/')
dirpath.mkdir(parents=True, exist_ok=True)
best_model_name = dirpath / f"sample-epoch={epoch+1:02d}-\
valid_loss={valid_loss:.03f}-valid_accuracy={valid_accuracy:.03f}.pth"
torch.save(model, best_model_name)
# 更新できなかった場合
else:
# カウンタを増やす
patience_count = patience_count + 1
# Early stoppingをチェック
if patience_count == params.early_stopping_patience:
# トレーニング終了
break
コード量は結構ありますが、お手製感もあって個人的にはこちらも結構好きです。
実際には、全体の見通しを良くするため、ここから更にtrainのステップ単位やvalidのステップ単位に関数化することも多いです。
推論のテスト
念のため、保存したモデルで同じ推論結果となるかテストします。
new_model = torch.load(best_model_name)
# 勾配計算をしないようにするコンテキストマネージャ
with torch.no_grad():
# valid結果集計用の変数
valid_loss, valid_correct = 0, 0
# valid用のループ
for X, y in tqdm(valid_dataloader,
total=len(valid_dataloader), ascii=True, desc="valid"):
X, y = X.to(device), y.to(device)
# 推論
pred = new_model(X)
# ロス計算
loss = loss_fn(pred, y)
# ロスの値を加算
valid_loss += loss.item()
# 正解数をカウント
valid_correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# ロスの平均化
num_batches = len(valid_dataloader)
valid_loss = valid_loss / num_batches
# 正解数を正解率に換算
size = len(valid_dataloader.dataset)
valid_accuracy = valid_correct / size
print(f"val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
出力は以下で、ベストな結果と一致することを確認できました。
valid: 100%|##########| 313/313 [00:00<00:00, 329.23it/s] val_loss: 0.347 - val_accuracy: 0.876
これをPyTorch Lightningでやってみる
インストール
Colab環境にPyTorch Lightningは入っていないため、インストールが必要です。
!pip install pytorch-lightning
インポート
とりあえずシンプルに以下だけでOKです。
import pytorch_lightning as pl
pl.LightningModuleについて
pl.LightningModuleを継承して実装していきます。
pl.LightningModuleには、PyTorchのnn.Moduleと同様に__init__やforwardなどを記述できるほか、
様々なトレーニングの時点に対応するHooksが準備されており、それらを記述することで学習プロセス全体を定義することが可能です。
Hooksは以下のページの動画を見るとイメージが分かりやすいです。
今回はその中で、以下のHooksを記述していきます。
- configure_optimizers
- on_train_epoch_start
- training_step
- validation_step
- validation_epoch_end
- training_epoch_end
- on_train_epoch_end
これらは疑似コードで表現すると、以下のようなタイミングで呼び出されます。
# 学習開始時の処理
# 今回はコンソールのログ出力に使用
on_train_start()
# オプティマイザ
configure_optimizers()
for epoch in epochs:
# エポック開始時の処理
# 今回はコンソールのログ出力に使用
on_train_epoch_start()
# 学習のバッチループ
train_outs = []
for batch_idx, batch in enumerate(train_dataloader()):
# 学習のバッチ処理
out = training_step(batch, batch_idx)
train_outs.append(out)
# validデータでの検証
# NOTE: 通常エポック終了時に実行されるが、途中のバッチ時の実行にも対応
if should_check_val:
# 検証のバッチループ
val_outs = []
for val_batch_idx, val_batch in enumerate(val_dataloader()):
# 検証のバッチ処理
out = validation_step(val_batch, val_batch_idx)
val_outs.append(out)
# 検証の全バッチ出力を集計
validation_epoch_end(train_outs)
# 学習の全バッチ出力を集計
training_epoch_end(train_outs)
# エポック終了時の処理
# 今回はコンソールのログ出力に使用
on_train_epoch_end()
# 学習終了時の処理
# 今回はコンソールのログ出力に使用
on_train_end()
validationの処理は、trainingのエポックに組み込まれていることに注意が必要です。
実際にvalidationの処理は1エポック終了時以外に、1バッチ終了時にも実行することが想定されています。
すべてのHooksのより細かい挙動は以下を参照ください。
pl.LightningModuleの定義
では、pl.LightningModuleを定義していきます。
class SampleLitModule(pl.LightningModule):
# PyTorchのnn.Moduleと同様にコンストラクタを記述可能
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
self.loss_fn = nn.CrossEntropyLoss()
# コンソールログ出力用の変数
self.log_outputs = {}
# PyTorchのnn.Moduleと同様にforwardを記述可能で、self(x)で推論を実行できる
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
# オプティマイザの定義
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=params.learning_rate)
return optimizer
# 学習のバッチ実行処理
# 戻り値は、以降のtraining_epoch_endでリスト形式で利用可能
def training_step(self, batch, batch_index):
X, y = batch
pred = self(X)
loss = self.loss_fn(pred, y)
return {'loss': loss, 'correct': (pred.argmax(1) == y).type(torch.float)}
# 学習の全バッチ終了時の処理
# ロスの集計などを行う
def training_epoch_end(self, outputs) -> None:
train_loss = torch.stack([x['loss'] for x in outputs]).mean()
train_accuracy = torch.cat([x['correct'] for x in outputs]).mean()
self.log_dict({"loss": train_loss, "accuracy": train_accuracy})
self.log_outputs["loss"] = train_loss
self.log_outputs["accuracy"] = train_accuracy
return
# 検証のバッチ実行処理
# 戻り値は、以降のvalidation_epoch_endでリスト形式で利用可能
def validation_step(self, batch, batch_index):
X, y = batch
pred = self(X)
loss = self.loss_fn(pred, y)
return {'val_loss': loss, 'val_correct': (pred.argmax(1) == y).type(torch.float)}
# 検証の全バッチ終了時の処理
# ロスの集計などを行う
def validation_epoch_end(self, outputs) -> None:
valid_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
valid_accuracy = torch.cat([x['val_correct'] for x in outputs]).mean()
self.log_dict({"valid_loss": valid_loss, "valid_accuracy": valid_accuracy})
self.log_outputs["valid_loss"] = valid_loss
self.log_outputs["valid_accuracy"] = valid_accuracy
return
# エポック開始時の処理
# 今回はコンソールのログ出力に使用
def on_train_epoch_start(self) -> None:
self.print(f"Epoch {self.trainer.current_epoch+1}/{self.trainer.max_epochs}")
return super().on_train_epoch_start()
# エポック終了時の処理
# 今回はコンソールのログ出力に使用
def on_train_epoch_end(self) -> None:
train_loss = self.log_outputs["loss"]
train_accuracy = self.log_outputs["accuracy"]
valid_loss = self.log_outputs["valid_loss"]
valid_accuracy = self.log_outputs["valid_accuracy"]
self.print(f"loss: {train_loss:.3f} - accuracy: {train_accuracy:.3f} - \
val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
return super().on_train_epoch_end()
# 学習開始時の処理
# 今回はコンソールのログ出力に使用
def on_train_start(self) -> None:
self.print(f"Train start")
return super().on_train_start()
# 学習終了時の処理
# 今回はコンソールのログ出力に使用
def on_train_end(self) -> None:
self.print(f"Train end")
return super().on_train_end()
EarlyStopping実装
pl.LightningModuleとは別にEarlyStoppingを実装します。
PyTorch LightningにはEarlyStoppingを実現するためのコールバックがあるため、そちらを使います。
from pytorch_lightning.callbacks import EarlyStopping
callbacks = []
if params.early_stopping:
callbacks.append(
EarlyStopping(monitor='valid_loss', patience=params.early_stopping_patience)
)
callbacksは、後述のTrainerに引数として渡します。
モデル保存
モデルの保存もコールバックを用いて自動で行うことができます。
ベストなモデルを保存する際に、監視する値をmonitor引数で与えます。
その他、上位何件を残すかなど、様々な設定が可能です。
from pytorch_lightning.callbacks import ModelCheckpoint
checkpoint_callback = ModelCheckpoint(
monitor="valid_loss",
dirpath="./pl-checkpoints",
filename="sample-{epoch:02d}-{valid_loss:.03f}-{valid_accuracy:.03f}",
save_top_k=3,
mode="min",
)
callbacks.append(checkpoint_callback)
トレーニング
準備ができたので、トレーニングはTrainerクラスを使って実行します。
# LightningModuleをインスタンス化
model = SampleLitModule()
# Trainer定義
trainer = pl.Trainer(
max_epochs=params.max_epochs,
callbacks=callbacks,
)
# トレーニング実行
trainer.fit(
model=model,
train_dataloaders=train_dataloader,
val_dataloaders=valid_dataloader,
)
こちらで以下のようにトレーニングが開始されます。
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: False INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs /usr/local/lib/python3.7/dist-packages/pytorch_lightning/trainer/trainer.py:1767: PossibleUserWarning: GPU available but not used. Set `accelerator` and `devices` using `Trainer(accelerator='gpu', devices=1)`. category=PossibleUserWarning, WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: /content/lightning_logs INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ------------------------------------------------------- 0 | flatten | Flatten | 0 1 | linear_relu_stack | Sequential | 101 K 2 | loss_fn | CrossEntropyLoss | 0 ------------------------------------------------------- 101 K Trainable params 0 Non-trainable params 101 K Total params 0.407 Total estimated model params size (MB) Train start Epoch 1/30 loss: 0.515 - accuracy: 0.818 - val_loss: 0.459 - val_accuracy: 0.837 Epoch 2/30 loss: 0.382 - accuracy: 0.862 - val_loss: 0.421 - val_accuracy: 0.850 ...
推論のテスト
同様に、保存したモデルで同じような推論ができるか念のためテストします。
ベストだったモデルのパスはcheckpoint_callback.best_model_pathに保持されるため、それを用います。
# モデル読み込み
new_model = SampleLitModule.load_from_checkpoint(
checkpoint_path=checkpoint_callback.best_model_path
)
# valid結果集計用の変数
valid_loss, valid_correct = 0, 0
# valid用のループ
for X, y in tqdm(valid_dataloader, total=len(valid_dataloader), ascii=True, desc="valid"):
# 推論
pred = new_model(X)
# ロス計算
loss = loss_fn(pred, y)
# ロスの値を加算
valid_loss += loss.item()
# 正解数をカウント
valid_correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# ロスの平均化
num_batches = len(valid_dataloader)
valid_loss = valid_loss / num_batches
# 正解数を正解率に換算
size = len(valid_dataloader.dataset)
valid_accuracy = valid_correct / size
print(f"val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
出力は以下で、ベストな結果と一致することを確認できました。
valid: 100%|##########| 313/313 [00:01<00:00, 222.34it/s] val_loss: 0.352 - val_accuracy: 0.877
さらに応用的な話
pl.LightningDataModuleの使用
PyTorch Lightningでは、前述のようにTrainerクラスのfit時にDataLoaderを直接与えたり、pl.LightningModuleに記述することも可能ですが、
データ周りの処理を別管理で定義するために、pl.LightningDataModuleというクラスがあります。
実際前処理が多くなると別管理とした方が見通しが良くなるケースがあります。
こちらを用いて、実装してみます。
class SampleDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str="data", batch_size: int = 32):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
# データセットをダウンロードするなどの読み込み処理を記述
# trainデータを分割したい場合などもここで実行可能
def setup(self, stage):
self.train_data = datasets.FashionMNIST(root=self.data_dir, train=True ,
download=True, transform=ToTensor())
self.valid_data = datasets.FashionMNIST(root=self.data_dir, train=False,
download=True, transform=ToTensor())
# 学習用のデータローダー
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size)
# 検証用のデータローダー
def val_dataloader(self):
return DataLoader(self.valid_data, batch_size=self.batch_size)
Callbackの使用
さきほど、pl.LightningModuleに記載したHookのうち、
以下のものはCallbackクラスとして別定義のクラスとすることが可能です。
- on_train_start
- on_train_epoch_start
- on_train_epoch_end
- on_train_end
これらのHooksは、学習そのものというよりかはログを出力する用途などが多いため、 別管理にする方が見通しが良くなるケースがあります。
こちらを用いて、実装してみます。(pl.LightningModuleからは削除)
from pytorch_lightning.callbacks import Callback
class PrintCallback(Callback):
# エポック開始時の処理
# 今回はコンソールのログ出力に使用
def on_train_epoch_start(self, trainer: "pl.Trainer", pl_module: "pl.LightningModule") -> None:
pl_module.print(f"Epoch {trainer.current_epoch+1}/{trainer.max_epochs}")
return super().on_train_epoch_start(trainer, pl_module)
# エポック終了時の処理
# 今回はコンソールのログ出力に使用
def on_train_epoch_end(self, trainer: "pl.Trainer", pl_module: "pl.LightningModule") -> None:
train_loss = pl_module.log_outputs["loss"]
train_accuracy = pl_module.log_outputs["accuracy"]
valid_loss = pl_module.log_outputs["valid_loss"]
valid_accuracy = pl_module.log_outputs["valid_accuracy"]
pl_module.print(f"loss: {train_loss:.3f} - accuracy: {train_accuracy:.3f} - \
val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
return super().on_train_epoch_start(trainer, pl_module)
# 学習開始時の処理
# 今回はコンソールのログ出力に使用
def on_train_start(self, trainer: "pl.Trainer", pl_module: "pl.LightningModule") -> None:
pl_module.print(f"Train start")
return super().on_train_start(trainer, pl_module)
# 学習終了時の処理
# 今回はコンソールのログ出力に使用
def on_train_end(self, trainer: "pl.Trainer", pl_module: "pl.LightningModule") -> None:
pl_module.print(f"Train end")
return super().on_train_end(trainer, pl_module)
nn.Moduleとpl.LightningModuleの分割
pl.LightningModuleは、モデル定義そのもののnn.Moduleとは無関係な学習プロセスに関わる処理も含んでいますので、
モデルが複雑になる場合、モデルそのものの定義は別クラスとしたくなることもあるかもしれません。
その場合は、コンストラクタ内でnn.Moduleをインスタンス化する形で呼び出して実装した方が良さそうです。
(この話自体はPyTorch Lightningとは無関係な設計の好みの話ではありますが...)
なので、以下のように変更してみました。
class SampleLitModel(pl.LightningModule):
# モデル定義自体は別途
def __init__(self):
super().__init__()
self.model = SamplePyTorchModel()
self.loss_fn = nn.CrossEntropyLoss()
# コンソールログ出力用の変数
self.log_outputs = {}
# forwardは、単にself.modelで処理する
def forward(self, x):
return self.model(x)
# オプティマイザの定義
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=params.learning_rate)
return optimizer
# 学習のバッチ実行処理
# 戻り値は、以降のtraining_epoch_endでリスト形式で利用可能
def training_step(self, batch, batch_index):
X, y = batch
pred = self(X)
loss = self.loss_fn(pred, y)
return {'loss': loss, 'correct': (pred.argmax(1) == y).type(torch.float)}
# 学習の全バッチ終了時の処理
# ロスの集計などを行う
def training_epoch_end(self, outputs) -> None:
train_loss = torch.stack([x['loss'] for x in outputs]).mean()
train_accuracy = torch.cat([x['correct'] for x in outputs]).mean()
self.log_dict({"loss": train_loss, "accuracy": train_accuracy})
self.log_outputs["loss"] = train_loss
self.log_outputs["accuracy"] = train_accuracy
return
# 検証のバッチ実行処理
# 戻り値は、以降のvalidation_epoch_endでリスト形式で利用可能
def validation_step(self, batch, batch_index):
X, y = batch
pred = self(X)
loss = self.loss_fn(pred, y)
return {'val_loss': loss, 'val_correct': (pred.argmax(1) == y).type(torch.float)}
# 検証の全バッチ終了時の処理
# ロスの集計などを行う
def validation_epoch_end(self, outputs) -> None:
valid_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
valid_accuracy = torch.cat([x['val_correct'] for x in outputs]).mean()
self.log_dict({"valid_loss": valid_loss, "valid_accuracy": valid_accuracy})
self.log_outputs["valid_loss"] = valid_loss
self.log_outputs["valid_accuracy"] = valid_accuracy
return
コールバックの設定
Trainer実行前にモデルの保存先などを変更したいため、再度コールバックを定義します。
callbacks = []
# EarlyStopping
if params.early_stopping:
callbacks.append(
EarlyStopping(monitor='valid_loss', patience=params.early_stopping_patience)
)
# モデル保存用
checkpoint_callback = ModelCheckpoint(
monitor="valid_loss",
dirpath="./pl-checkpoints-2",
filename="sample-{epoch:02d}-{valid_loss:.03f}-{valid_accuracy:.03f}",
save_top_k=3,
mode="min",
)
callbacks.append(checkpoint_callback)
# 定義したコールバックも追加
callbacks.append(PrintCallback())
トレーニング
準備ができたので、Trainerを使ってトレーニングをします。
fitには、DataLoaderの代わりにDataModuleを与えます。
# LightningModuleをインスタンス化
model = SampleLitModel()
# Trainer定義
trainer = pl.Trainer(
max_epochs=params.max_epochs,
callbacks=callbacks,
)
# トレーニング実行
# DataLoaderの代わりに、DataModuleを与える
trainer.fit(
model=model,
datamodule=SampleDataModule(batch_size=params.batch_size),
)
こちらで先ほどと同様に、以下のようにトレーニングが開始されます。
推論のテスト
同様に、保存したモデルで同じような推論ができるか念のためテストします。
# モデル読み込み
new_model = SampleLitModule.load_from_checkpoint(
checkpoint_path=checkpoint_callback.best_model_path
)
# valid結果集計用の変数
valid_loss, valid_correct = 0, 0
# valid用のループ
for X, y in tqdm(valid_dataloader, total=len(valid_dataloader), ascii=True, desc="valid"):
# 推論
pred = new_model(X)
# ロス計算
loss = loss_fn(pred, y)
# ロスの値を加算
valid_loss += loss.item()
# 正解数をカウント
valid_correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# ロスの平均化
num_batches = len(valid_dataloader)
valid_loss = valid_loss / num_batches
# 正解数を正解率に換算
size = len(valid_dataloader.dataset)
valid_accuracy = valid_correct / size
print(f"val_loss: {valid_loss:.3f} - val_accuracy: {valid_accuracy:.3f}")
出力は以下で、ベストな結果と一致することを確認できました。
valid: 100%|##########| 313/313 [00:01<00:00, 222.34it/s] val_loss: 0.352 - val_accuracy: 0.877
TensorBoardによる可視化
PyTorch LightningはTensorBoardによる可視化にも対応していますので、最後に紹介します。
PyTorch Lightningの出力は、デフォルトで./lightning_logsに保存されるため、そのパスを指定してTensorBoardを起動します。
%reload_ext tensorboard %tensorboard --logdir=lightning_logs/
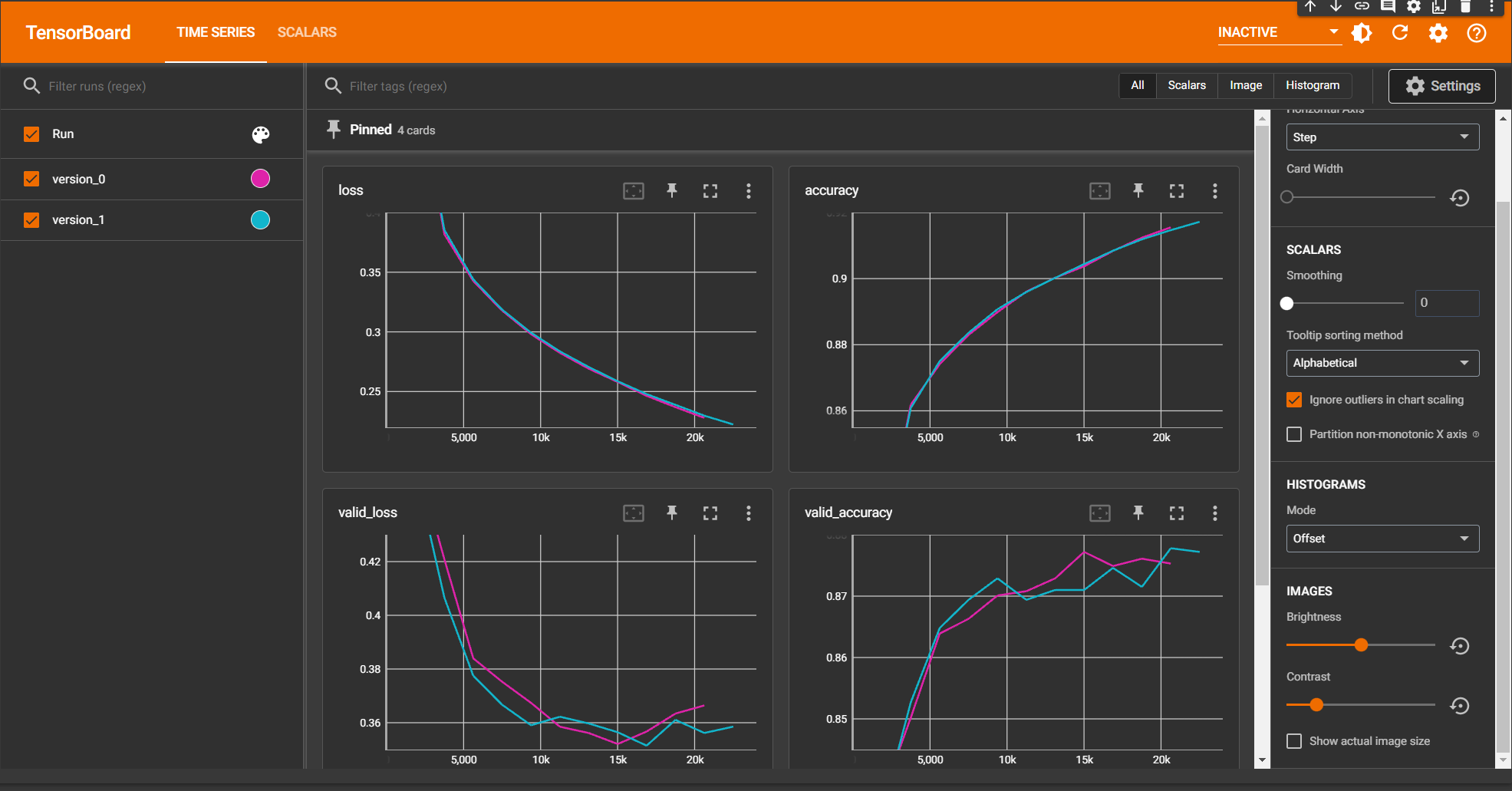
以下のような画面が起動されます。
ちょうど今回は2トライしましたので、それぞれの結果を比較することができています。
まとめ
いかがでしたでしょうか?
実際に触ってみると、Hookによってかなりわかりやすくコードが書けるよう構成されていることが分かりました。 カスタマイズも非常にしやすく、抽象化されすぎていない印象で、研究用途を目指して作られていることが分かります。
まだまだ多くの機能を試せていませんが、今後そちらも記事にできたらと思います。
本記事がPyTorch Lightningを使われる方の参考になれば幸いです。






![[Python] 関数定義時の特殊な引数宣言についてまとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-a873a00568e5285b2051ff6c5aae2c3d/febef60aecfe576a837a7efcb96625eb/python_icatch.png)
